| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
Week-1
Math 183 • Statistical Methods • Spring 2026
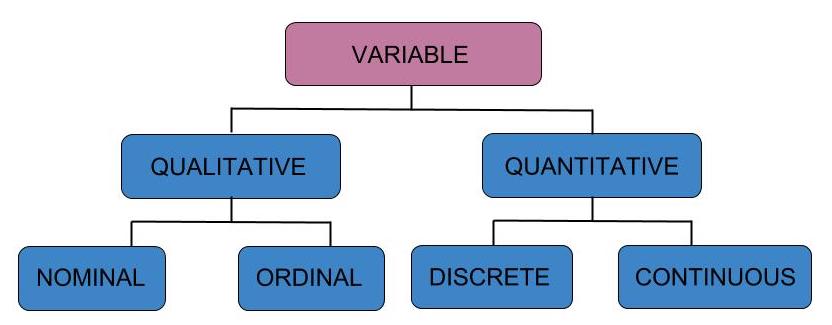
Types of Variables
Warning
Sometimes computers can’t (or won’t) understand the difference between different types of variables. It’s up to us to tell them!
Bar chart
data$cyl %>%
table %>%
barplot(col=c("red", "white", "blue"))
## Equivalently
barplot(table(data$cyl), col=c("red", "white", "blue"))Scatterplot
data %>%
select(mpg, disp) %>%
plot(col="dodgerblue", pch=20)
# Equivalently
plot(data[, c("mpg", "disp")]col="dodgerblue", pch=20)Boxplot
boxplot(mpg~cyl, data)
Boxplot
abline(h=c(up_q, low_q, m), col=c("red", "blue", "black"))
Histogram
hist(data$disp)
Histogram
hist(data$disp, breaks=20)
Histogram
hist(data$disp, breaks=3)
Histogram
hist(data$disp, freq=F)
Histogram
hist(data$disp, freq=F)
lines(density(data$disp), col="red")
Flat

Right Skewed

Symmetric

Left Skewed

Measures of Dispersion: Variance
Which of the following histograms exhibits more variability?


Variance, as the name suggests, is a measure of this variability.
What effect does variance have on our perception of the data?
Lower Quantile
Lower Quantile
For \(0 \le \alpha \le 1\), the lower \(\alpha\)–quantile of \(x_1, x_2, \ldots, x_n\) is the value for which at least \(\alpha\) fraction of the points have a value less than or equal to it.
\(Q_{0.1}\) quantile

Lower Quantile
Lower Quantile
For \(0 \le \alpha \le 1\), the lower \(\alpha\)–quantile of \(x_1, x_2, \ldots, x_n\) is the value for which at least \(\alpha\) fraction of the points have a value less than or equal to it.
\(Q_{0.6}\) quantile

Lower Quantile
Lower Quantile
For \(0 \le \alpha \le 1\), the lower \(\alpha\)–quantile of \(x_1, x_2, \ldots, x_n\) is the value for which at least \(\alpha\) fraction of the points have a value less than or equal to it.
\(Q_{0.95}\) quantile

Upper Quantile
Upper Quantile
For \(0 \le \alpha \le 1\), the upper \(\alpha\)–quantile of \(x_1, x_2, \ldots, x_n\) is the value for which at least \(\alpha\) fraction of the points have a value greater or equal to it.
\(q_{0.05}\) quantile

Upper Quantile
Upper Quantile
For \(0 \le \alpha \le 1\), the upper \(\alpha\)–quantile of \(x_1, x_2, \ldots, x_n\) is the value for which at least \(\alpha\) fraction of the points have a value greater or equal to it.
\(q_{0.1}\) quantile

Upper Quantile
Upper Quantile
For \(0 \le \alpha \le 1\), the upper \(\alpha\)–quantile of \(x_1, x_2, \ldots, x_n\) is the value for which at least \(\alpha\) fraction of the points have a value greater or equal to it.
\(q_{0.95}\) quantile
